DynamoDB Tips
This post is a small collection of things that are important to bear in mind when working with DynamoDB, and the list below describes what is covered here:
- Limits
- The different ways DynamoDB manages the limits on throughput and the options available
But just 2 things? Things can get complicated when breaking them down, which for me, is sometimes confusing enough.
Motivation
So, instead of having to search for things on AWS documents, I prefer to maintain a simplified page with some reminders for myself (which can also be useful for someone else). This page is intended to be used just as a reference or in other words, it’s not the best place to deeply understand the concepts (this is best covered by AWS docs).
The main focus of this page, is around the different options to consider in terms of how to get the best out of the capacity available for reads and writes for a table. As a reminder, when using provisioned mode (more about that later), the capacity is defined in terms of reads and writes per second aka RCUs (read capacity units) and WCUs (write capacity units). When using on-demand mode, it’s called read request units and write request units respectivelly.
Some details on limits
Before moving on, I want to list limits on sizes and throughput:
- 1 RCU = 1 strongly consistent read per second, for items up to 4KB;
- 1 RCU = 2 eventual consistent reads per second, for items up to 4KB;
- 1 WCU = 1 write/s for items up to 1KB (regardless if it is strongly or eventual consistent);
- Transactional requests require double the capacity (the size in KB remains the same);
- Maximum item size within a table: 400KB;
- 40,000 RCUs/WCUs per table;
- 3,000 RCUs per partition;
- 1,000 WCUs per partition;
- Batch write operation can write up to 16MB for a single call (can accomodate 25 puts or deletes with each item not being larger than 400KB);
- Batch get operation can read up to 16MB for a single call (100 items)
Options available
It’s important to mention, that the limits presented here are imposed by the cost of resources and maintenance and of course, AWS needs to charge the companies in some way. But in order to make things flexible enough, AWS provides different options so companies can decide on how to be charged considering the demands of their applications.
Capacity modes
I don’t want to dive into the details on how AWS charges (there’s a lot of things to be considered), but the main things to consider are throughput and amount of data stored. I am going to focus just on throughput, or in other words, capacity for reads and writes.
Initially, DynamoDB offered only provisioned mode, where you specify the number of RCUs and WCUs for each table at creation (and can adjust them later). This mode works well when your application’s read and write requirements are predictable and throughput remains relatively stable. With provisioned mode, you can also enable auto-scaling to help DynamoDB automatically adjust capacity as your application’s workload changes gradually.
For applications where workloads are unpredictable and can experience irregular peaks, AWS introduced on-demand capacity mode. With this mode, you are charged only for the read and write requests you actually use. However, if your application’s traffic is stable and predictable, on-demand mode may be more expensive compared to provisioned capacity.
A table can be changed to use one mode or the other (an operation that can take a few minutes) but just once a day. As per AWS docs:
You can switch between read/write capacity modes once every 24 hours…
Scaling with on-demand capacity
DynamoDB automatically allocates more capacity when the workload for an application increases, demanding more capacity than what was available as per the last peak. However, DynamoDB can accommodate up to double the previous peak within 30 minutes whilst allowing for sustained traffic without throttlings. If the traffic of an application more than doubles within a row of 30 minutes, the application can experience throttling.
Autoscaling
When using provisioned capacity mode, a table can be created with auto scaling out of the box. When creating from AWS console, those are the options:
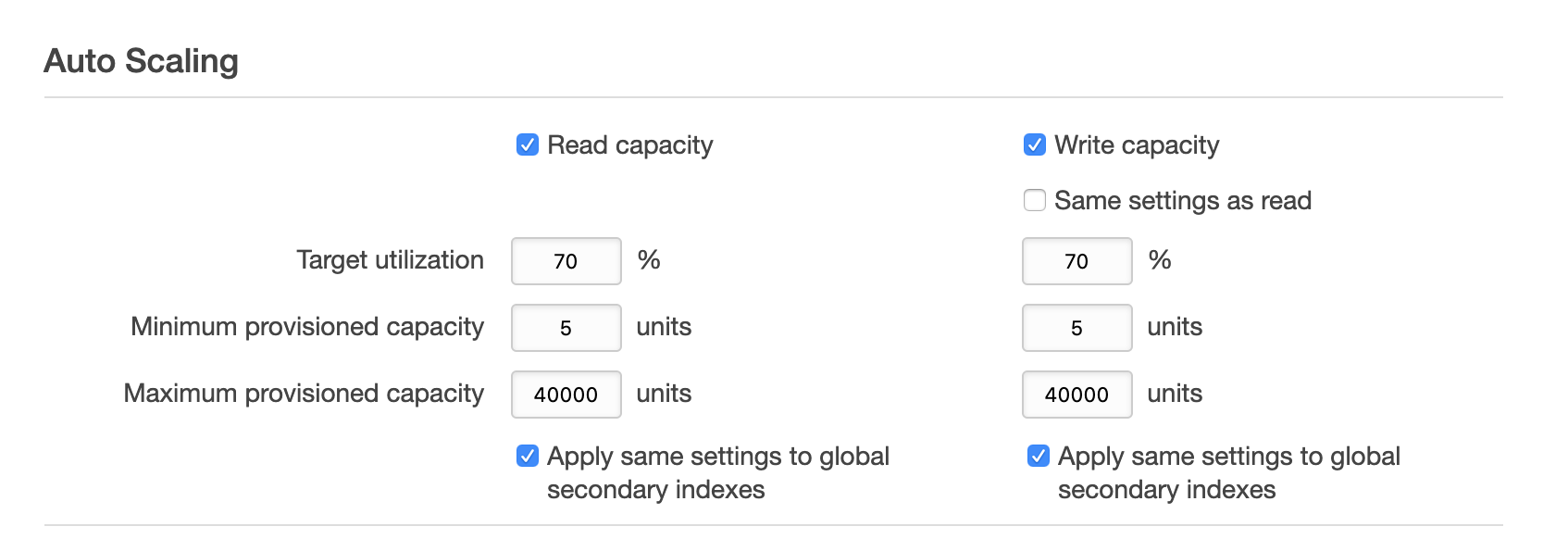
As can be seen in the previous screenshot, we can set the lower and upper limits as well as the target utilisation. As per AWS docs, the definition of target utilisation is:
the percentage of consumed provisioned throughput at a point in time. Application Auto Scaling uses a target tracking algorithm to adjust the provisioned throughput of the table (or index) upward or downward in response to actual workloads, so that the actual capacity utilization remains at or near your target utilization.
Although this message might be quite clear for most people, maybe for me as a non-native-english-speaker, is was hard to understand at the very first moment. It would be clear for me if it was described as:
Application auto scaling, adjusts the capacity upwards or downwards so it can allow the application to consume the same capacity (i.e keep consuming 70% of total capacity) it was consuming before changing the throughput of the table.
Let me add some simple (maybe naive) examples:
Provisioned RCU = 100
Provisioned WCU = 100
Target utilisation = 70%
Current workload demand = 110 RCUs
In order to keep 110 RCUs representing 70% of the provisioned capacity, Application auto scaling needs to increase the RCU size to ~157.
If the target utilisation was 20%, Application auto scaling would increase it to something around 550 RCUs. This simple math can be better represented with the following graphic:
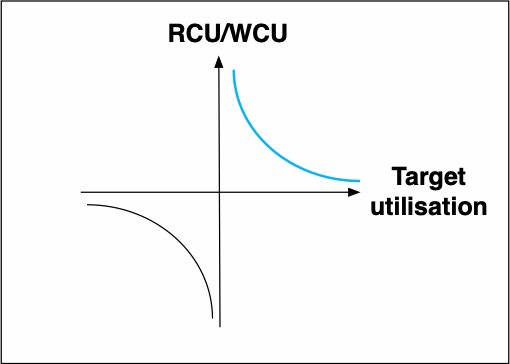
Looking at the previous image, is easy to figure out why the target utilisation can be a value between 20 and 90 percent (100% would lead the capacity to stay the same and as the percentage gets close to 0 the amount of capacity tends to infinity).
How it works
When a table is created with provisioned capacity + auto scaling, Application Auto Scaling creates CloudWatch alarms that will be later used to send an SNS notification and/or notify Application Auto Scaling to increase or decrease the capacity as needed. CloudWatch will trigger an alarm in case that the table’s consumed capacity exceeds the target utilisation.
The changes to the table won’t be applied until the capacity exceeds the target utilisation for a sustained period (which is specified as several minutes by AWS - not quite clear).
Burst capacity
DynamoDB saves up to 5 minutes of unused capacity, which can be used when the provisioned capacity is exhausted for a limited period. This can be used when there are occasional bursts on reads or writes by an application and can also be used by DynamoDB to run internal operations.
This can be combined with auto scaling to prevent throttling, however, the developer still needs to know the patterns of capacity consumption.
Adaptive capacity
This helps when the capacity of a table is consumed unevenly from its partitions (problem also known as hot partition). It allows for a hot partition to use capacity available from other partitions as long as it doesn’t exceed the provisioned capacity for the table.
In the past, it used to take 5-30 minutes for DynamoDB to recover from a capacity exhaustion and start using adaptive capacity, but now it happens instantly.